
Биометрическая дедупликация
В биометрических системах национального масштаба часто хранятся десятки или сотни миллионов отпечатков пальцев. Как правило, эти данные накапливаются годами: они приходят из различных регионов и собираются тысячами и десятками тысяч разных сотрудников профильных ведомств.
Из-за ошибок, вызванных человеческим фактором или техническими сбоями, а иногда и из-за злонамеренных действий, а также при отсутствии проверки на дубликаты при внесении отпечатков биометрические базы данных национального масштаба сталкиваются с проблемой ошибок и дубликатов.
В биометрических системах национального масштаба часто хранятся десятки или сотни миллионов отпечатков пальцев. Как правило, эти данные накапливаются годами: они приходят из различных регионов и собираются тысячами и десятками тысяч разных сотрудников профильных ведомств.
Из-за ошибок, вызванных человеческим фактором или техническими сбоями, а иногда и из-за злонамеренных действий, а также при отсутствии проверки на дубликаты при внесении отпечатков биометрические базы данных национального масштаба сталкиваются с проблемой ошибок и дубликатов.
- Полный дубликат записиВсе отпечатки пальцев в записи полностью повторяют другую запись. Такие дубликаты могут появиться в базе данных, например, при выдаче нового ID без проверки на дубликат.
- Ошибки внутри записиОдин и тот же отпечаток пальца одного человека добавлен в запись несколько раз - как отпечаток другого пальца того же человека. Такие дубликаты часто вызваны ошибками в работе оператора.
- Частичный дубликатОдин или несколько отпечатков пальцев дублированы из другой записи. Причиной может быть ошибка оператора, особенно если он добавляет отпечатки в базу из папки на компьютере, где уже лежат сканы.
Подавляющее большинство этих ошибок можно исправить с помощью процедуры дедупликации.
Подавляющее большинство этих ошибок можно исправить с помощью процедуры дедупликации.
Использование таких подходов и большого количества оборудования делает задачу дедупликации огромных баз данных реализуемой на практике, но - по определению - это дает менее точный результат, чем при непосредственном сравнении всех отпечатков в базе друг с другом.
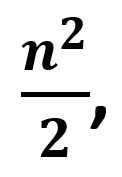
Полная дедупликация базы данных из 100 миллионов отпечатков с помощью нашего алгоритма занимает меньше 2х месяцев на одном сервере с одним процессором или менее 10 дней - на одном сервере с одной видеокартой*. При этом для дедупликации используется прямое сравнение "всего со всем", выполненное самым точным алгоритмом, что позволяет найти максимально возможное количество ошибок и дубликатов.
- Пары ID, где все отпечатки одинаковые (полный дубль записи)
- ID, где в записи есть дубликаты отпечатка (один и тот же палец внесен несколько раз в ту же запись)
- Пары ID с указанием позиции пальцев, где есть дубликаты одного или нескольких пальцев
программа для дедупликации - в подарок.
Пишите нам, чтобы узнать подробности!